One of the frustrating aspects of software development is that, often, the robustness and security defects that show up in deployment aren’t in the really big, complex components that keep us awake at night. Many times, the bugs that bite hardest are in “stupid” stuff — little administrative utilities, simple glue code, add-on features, and obscure non-standard configurations.
This isn’t a coincidence. In any large software project, design and testing are a tremendous effort. Big, complex components tend to get the respect they deserve. For the really hard stuff, there is more likely to be meaningful internal documentation, code review, and high-coverage unit and integration tests. By contrast, those comparatively trivial components on the periphery, perhaps delegated to an intern or written late in the development cycle, don’t attract the same kind of scrutiny as sexier core functionality.
Saving a Heap of Bother
Last fall, I noticed something odd while reviewing test results. On one machine, a pg_ctl process was sporadically dumping core. In each case, the test actually ran successfully to completion. This was a rare event in third-party code with no apparent side-effects, but I still needed to solve the mystery of the crashing pg_ctl process.
The core dump showed a crash in malloc due to heap corruption, but the stack trace was irrelevant to the cause of the corruption. Running under valgrind or in a debugger, I wasn’t able to replicate this rare event.
For those unfamiliar with PostgreSQL, the humble purpose of pg_ctl according to its man page is to “start, stop, or restart a PostgreSQL server.” Look again at the top-level hierarchical graph of PostgreSQL from the previous post on CodeSonar’s visualization tool:

If you squint, you can see pg_ctl as the smallest node on the right in the bin directory. Size here represents lines of code. Far removed from the complexity of the PostgreSQL backend, pg_ctl seems an unlikely site for a memory corruption heisenbug.
But by drilling down to pg_ctl and annotating nodes with CodeSonar warning metrics, I could easily find the offending function. First, take a look at the source of readfile and try to spot the mistake.
/*
* get the lines from a text file - return NULL if file can't be opened
*/
static char **
readfile(const char *path)
{
FILE *infile;
int maxlength = 1,
linelen = 0;
int nlines = 0;
char **result;
char *buffer;
int c;
if ((infile = fopen(path, "r")) == NULL)
return NULL;
/* pass over the file twice - the first time to size the result */
while ((c = fgetc(infile)) != EOF)
{
linelen++;
if (c == 'n')
{
nlines++;
if (linelen > maxlength)
maxlength = linelen;
linelen = 0;
}
}
/* handle last line without a terminating newline (yuck) */
if (linelen)
nlines++;
if (linelen > maxlength)
maxlength = linelen;
/* set up the result and the line buffer */
result = (char **) pg_malloc((nlines + 1) * sizeof(char *));
buffer = (char *) pg_malloc(maxlength + 1);
/* now reprocess the file and store the lines */
rewind(infile);
nlines = 0;
while (fgets(buffer, maxlength + 1, infile) != NULL)
result[nlines++] = xstrdup(buffer);
fclose(infile);
free(buffer);
result[nlines] = NULL;
return result;
}
|
| (Source listing released under the PostgreSQL License.) |
Now take a look at how visualization made finding the cause of this vexing crash simple:
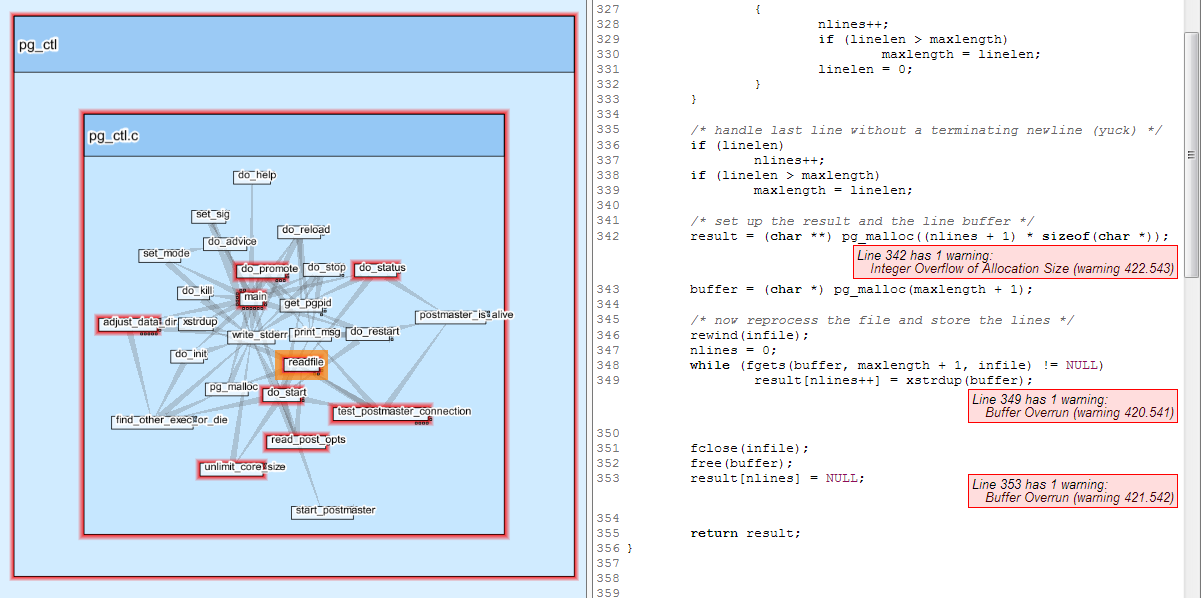
This is a flavor of filesystem time-of-check to time-of-use race condition (TOCTOU) leading to a heap buffer overrun. The readfile function reads the file once to determine how much heap to allocate, rewinds, and reads the file again into the allocated space. If the file has grown between the first and second reads, the allocated buffer is overflowed.
In this case, when pg_ctl is invoked with -w to wait for the postmaster to finish starting, readfile is called in a loop on the postmaster.pid file written out by the server. Our unlucky process made the function call midstream, and by setting the appropriate breakpoints, the crash is easily replicated. Mystery solved. If this wasn’t clear enough, the linked CodeSonar warning report would explain the path of the overrun step-by-step in plain English. Cross-referencing and visualization make navigating call graphs a snap. Although I used the visualization tool to track down this bug, it was also the first hit in a warning search for “buffer overrun” in pg_ctl.c:
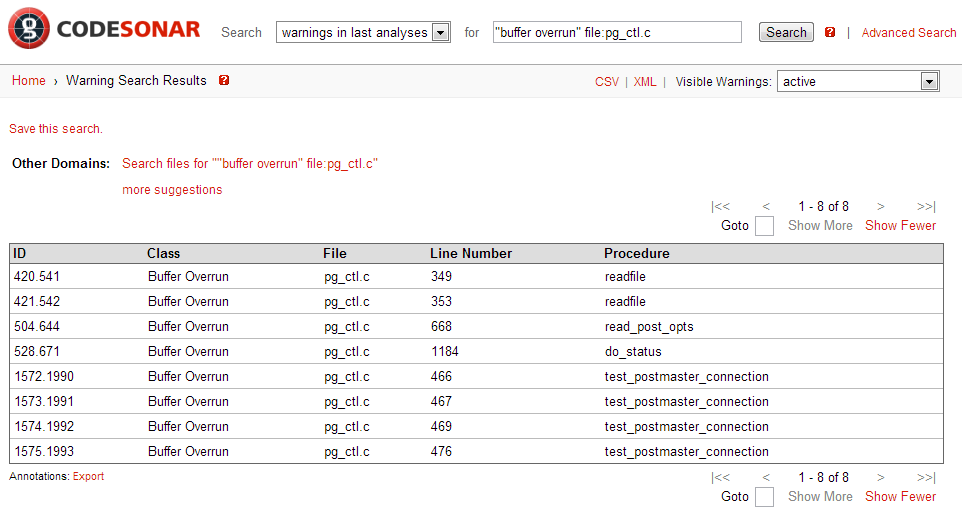
Some Bug Archaeology
But the readfile function, barely changed, dates from 2003. Why was I encountering this crash in 2012? I’ll come back to that question, but if you’ve followed me so far, you may find yourself wondering if this wasn’t all avoidable. As we’ve already seen, no code depends on pg_ctl, and pg_ctl itself has few calls into the backend. Does it really take 2,000 lines of memory-unsafe C code to “start, stop, or restart a PostgreSQL server?” Couldn’t you do that with … a shell script?
Since PostgreSQL follows an open development model, warts and all, a bit of digging reveals that pg_ctl was a shell script. Which brings us back to November 2003. PostgreSQL 7.4 was released, and a roadmap called for a port from the longtime Windows support under Cygwin to a native Windows service in a future release. Among the blockers was the collection of shell scripts in bin/ including initdb.sh and pg_ctl.sh. On Windows, PostgreSQL relied on Cygwin’s shell interpreter.
A contributor provided a port of initdb.sh to C, which included the readfile function to read various configuration files. Those files are typically hand-edited and not expected to change, so the usage of readfile here was “safe.” Shortly afterwards, a second contributor offered a port of pg_ctl.sh to C, which was unceremoniously rejected as low-quality. Six months later, the original contributor offered his own C port of pg_ctl.sh — copying the static readfile function verbatim, but now using it to read the postmaster options file created at startup. Perhaps due to passage of time, this conceivably violated readfile’s unwritten contract that file size cannot increase. Still, this remained a remote possibility as PostgreSQL 8.0 was finally released with native Windows support in January 2005, replacing the 419-line pg_ctl.sh script with 1,509 lines of C.
By the PostgreSQL 9.1 release, pg_ctl.c had grown to over 2,200 lines of C. Included was a well-intentioned commit to improve “pg_ctl -w start” server detection, which increased the complexity of the postmaster.pid file and called readfile on it in a loop. The trap set eight years earlier was sprung, and crashes became a realistic possibility. Fortunately, our testing process worked; after moving to PostgreSQL 9.1, we found and fixed the bug before bundling it with our release. CodeSonar even detected the duplicated code and linked the similar warning reports in pg_ctl and initdb even though they are separately compiled and linked in different directories.
A Widespread Problem
This harmless illustration is not to intended pick on the excellent PostgreSQL community. As far as I can tell, the net effect of this bug was to make scripts relying on pg_ctl’s return value slightly dodgy. But there is an endless supply of apparently harmless cruft causing serious mayhem. To name three more examples:
- A seminal web-based command injection vulnerability was a C-language CGI program called phf found in early versions of NCSA/Apache httpd, which provided a wrapper for CCSO Nameserver queries. Even then, the protocol was outdated and the script hardly used, but it was enabled by default and permitted arbitrary command injection. According to Kevin Mitnick’s book The Art of Intrusion, this vulnerability was used to hack the White House website in 1999.
- History repeats itself. In 2009, a command injection vulnerability was found in Nagios, again in a small standalone C-language CGI program that provided a simple WAP interface. WAP was as dated in 2009 as CCSO Nameserver in 1999, but statuswml.cgi was enabled by default and permitted arbitrary command injection.
- Coreutils ranks among the most scrutinized software packages of all time. But recently, Red Hat issued a security advisory for stack buffer overruns in sort, join, and uniq caused by an internationalization patch in Red Hat and SUSE based distributions. A user had reported this bug with a test case nearly a year ago.
Even expert programmers will still make mistakes in “easy” code. There is no substitute for thorough testing, but time and again testing falls short. Static analysis tools like CodeSonar are a valuable technology that complements testing and can often catch bugs that are missed otherwise. In addition, GrammaTech is doing active research in such areas as automated test generation, catching dangerous changes to software, and automated software hardening.
Lessons Learned
Hopefully this post will help motivate you to pay closer attention to the code you write. To close, here are a few reminders we can all use from time to time:
- Resist the temptation to copy and paste functions blindly from elsewhere in your codebase, or worse yet, from Stack Overflow. Prefer well-documented and tested library functions, and watch out for hidden preconditions. Practice mindful coding.
- On the flip side, when you write static helper functions or methods, don’t lard them with unnecessary preconditions, and make sure they are documented. Who knows where they will end up?
- Use the best tools for your requirements. There are plenty of reasons not to write shell scripts, but in 2014 you should have a better reason than “portability” for developing new code in C.
- Integrate a good static analysis tool in your build system, and pay attention when new warnings are introduced. CodeSonar is easily combined with any continuous integration platform to provide rapid notice of problematic changes.