I’m on a MISRA committee to specify a standard for code metrics (aka measures) for software quality. The committee was formed to fill a gap: there are no good comprehensive standards for code metrics. There are several lists of metrics that are available, such as the HIS (Hersteller Initiative Software) metrics, so we’re consulting those to gather the set that will end up in the new Misra standard.
I’ve never been a big fan of code metrics as a way of measuring interesting properties of code. At their worst, they are wielded as a weapon of fake science by those who don’t really get software. I regularly roll my eyes when I hear people earnestly proclaim that it is vitally important to keep the value of Cyclomatic Complexity below a fixed threshold (the shortcomings of cyclomatic complexity are well documented elsewhere so I won’t repeat them here.) At best, code metrics can be used as indicators of potential problems or rough approximations to quantity. IMHO, that’s the best way to think of them: as imprecise approximations.
Consequently I believe that metrics should exist and they should be well defined, which is why I was so horrified at what I found when I dug deeper into the metric commonly known as NPATH, which claims to be the count of acyclic paths in a function. In short, NPATH is profoundly wrong about what it claims to measure and its original sins have propagated widely so now many tools do the wrong thing too.
This interest was sparked by Roberto Bagnara who is also on the Misra committee and who has proposed a better definition of a metric that approximates an acyclic path count. In his paper (see Bagnara et al) they point out many of the same issues I observed, but they pull their punches on just how awful NPATH really is.
NPATH Definition
NPATH was first proposed by Nejmeh in 1988 in his paper “NPATH: a measure of execution path complexity and its applications.” It’s offered as a better alternative to Cyclomatic Complexity (see – even in 1988 many were aware of that metric’s limitations) and is supposed to measure the number of acyclic paths through a function. Nejmeh cites a 1986 tech report from Bell Labs that concludes that a value of 200 is the threshold that should not be exceeded.
Nejmeh’s paper describes how the metric should be computed by reasoning about how control flow graphs are created from syntactic structures, and how execution may flow along the paths. He then gives a syntax-directed definition of the metric.
The first sign of trouble is that very simple constructs that have exactly the same control flow graph are defined in strikingly different ways and so can yield very different values of the metric. Assuming that X, Y, and Z are constructs that have no branching (and that they terminate), then in C these three constructs have the same control flow:
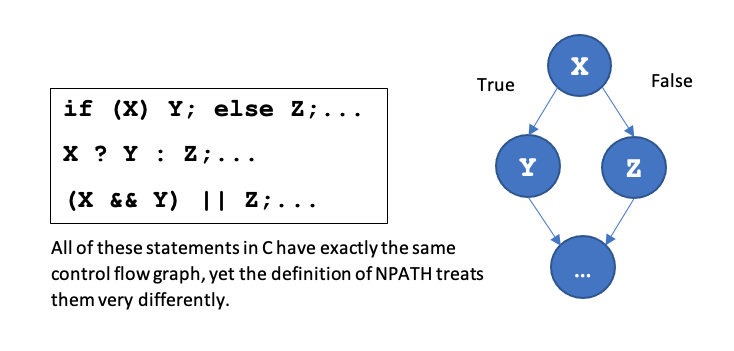
There are clearly and unambiguously two paths through each of these, but for the if statement, the definition can yield zero (depending on the structure of X, Y and Z), for other two the value is at least 2. The first one is just wrong, but for the last two the definition gives the correct value sometimes, and then only by accident.
The definition is given as a set of recursive equations. The parts that are relevant to the three conditionals above are as follows (paraphrased for clarity):
|
|
Structure |
Expression |
|
1 |
if (E) then S1; else S2; |
NP(E) + NP(S1) + NP(S2) |
|
2 |
E1 ? E2 : E3 |
NP(E1) + NP(E2) + NP(E3) + 2 |
|
3 |
Expressions |
Number of && and || operators in expression |
One would expect that these definitions would be somewhat consistent, but they’re not; why is there a +2 for the conditional statement? Why isn’t the definition for expressions recursive? (this inconsistency has been pointed out before; see this reddit thread for example.) That they are not consistent is indicative of a deeper problem.
Counting paths is a multiplicative thing. In a function with two statements, the number of paths through the function as a whole is the product of the number of paths through each of those statements. While Nejmeh’s definition specifies that, the unfortunate effect of the definition for expressions is that the value can be zero, so if one writes a statement in C that is just an expression and there are no && or || operators within, then that value of zero when multiplied with the values from the other statements can yield zero for the entire function, which is clearly absurd. (An argument that writing such an expression in a C program is bad practice is pretty weak, because C programmers do this stuff all the time for good reasons.)
It’s tempting to chalk these errors up to oversight, and that modest adjustments to the definition would correct the problem, but there’s much worse to come.
Look again at the definition for the if statement. Note that it is adding the number of paths from its components together. This is profoundly wrong; the number of paths should be the product of the number of paths through E, and the sum of the number through S1 and S2, i.e.:
NP(E) * (NP(S1) + NP(S2))
The definition for the conditional expression is similarly wrong. The same goes for the definitions of loops and switch statements in the paper. The definition for expressions is also fatally flawed.
There are other bad mistakes in the definition. The number of paths through a function call is defined to be 1, totally ignoring the paths through expressions that are the arguments to the function. Similarly, if a return statement has an expression, the number of paths through that is also ignored.
What seems to be a key flaw in the approach is that the author tried to treat statements and expressions differently. The +2 for the conditional expression indicates this conclusion, which is reinforced by the fact that the definition recurses into (most) parts of statements but not parts of expressions.
It would have been so much better and less error prone to define the metric in terms of the control flow graph instead of trying to do it in this syntax-directed manner. This would also have made it much easier to interpret the paper for languages other than C.
Tools that Compute NPATH
There are several tools that compute NPATH for different languages. Having found these errors in the original definition, I assumed that authors of tools would also have noticed the mistakes and corrected them when they wrote their implementation. However, I was shocked to find that was not the case. Several tools have blindly used the original definition while continuing to claim that the metric is yielding the number of acyclic paths. Here are three examples:
PHP programmers may be familiar with pdepend, which seems to be fairly popular. Unfortunately the code indicates that it implements the original broken definition of NPATH. To his credit the author appears to be aware of at least some of its shortcomings, but asserts that implementing it exactly as it was originally specified is still the right thing to do so as to be consistent (that’s not an unreasonable opinion, but I still disagree.)
Checkstyle is a tool for checking that Java programs adhere to a coding standard. Sadly, according to this page, it also implements the original defective algorithm.
PMD is also a widely used tool for checking Java programs. It also uses the buggy definition.
Although I concede that I did not do a comprehensive literature search on the subject, the only paper I know of that clearly points out the defects in NPATH is the Bagnara paper mentioned above.
Consequences of Poorly Defined Metrics
So how could such a profoundly bad definition have propagated so far with so little apparent realization that it is incorrect? Surely users of tools that compute NPATH must be basing decisions about their software on the value of the metric. This metric is in the HIS metrics standard that was agreed to by several large-scale automobile manufacturers, so the fact that it is so wrong may have resulted in bad decisions on software that is currently running in cars. Maybe that software is not adequately tested because NPATH badly understated the number of paths and the test engineers thought they could get away with fewer test cases. (Note that the HIS standard does not itself furnish a definition of this metric, but refers to tools that implement the original NPATH. However, the standard claims that the metric yields “the minimum number of necessary cases of test”, which is also completely wrong even for a correctly defined way of measuring the number of acyclic paths.)
Perhaps the real answer is that the value of the metric doesn’t actually matter that much; that in most cases the difference between what NPATH yields and the real value is inconsequential. Maybe the thresholds of acceptance are such that if NPATH is too high then that’s good enough to warrant refactoring the code, and the real number of acyclic paths would have been too high too so who cares? Or maybe there are generally so many other indicators of complexity that the number of functions where it might have mattered is tiny.
Regardless of why few people seem to know or care very much, there’s no excuse for continuing to use NPATH as it was originally defined. It simply does not measure anything close to what it is supposed to measure. Would engineers or scientists or any other practitioners of any other quantitative discipline put up with similar nonsense? It’s an embarrassment and a black eye for software engineering, so we should get rid of it. There are other ways of approximating acyclic path counts (e.g., Bagnara et al’s ACPATH) that are just as easy to implement, so let’s use those.